
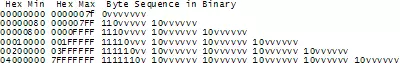
Is Unicode a 16-bit encoding?
Bạn đang đọc: Tìm hiểu Unicode
Nếu câu trả lời bạn chọn là Đúng, xin chúc mừng, bạn đã sai, đừng buồn vì ít ra bạn đã có một đồng chí là mình =))
Một điều mà nhiều người đến nay vẫn nhầm tưởng là Unicode sử dụng 16 bit để mã hóa, bởi vậy nó chỉ có thể mã hóa tối đa 65536 ký tự. Điều này hoàn toàn không chính xác.
Thực ra, phiên bản đầu tiên của Unicode đúng là sử dụng 16 bit để mã hóa, từ năm 1991 đến 1995. Nhưng từ khi Unicode 2.0 ra đời (06/1996), nó không còn sử dụng chỉ 16 bit để mã hóa nữa. Chuẩn Unicode mã hóa ký tự trong dải từ U+0000 đến U+10FFFF, tức là bao gồm không gian mã khoảng 21 bit. Tùy vào phương thức mã hóa được sử dụng (UTF-8, UTF-16, UTF-32), mỗi ký tự sẽ được biểu diễn bởi một chuỗi từ 1-4 đơn vị mã 8 bit (tương đương 1-4 byte), từ 1-2 đơn vị mã 16 bit, hoặc chỉ một đơn vị mã 32 bit duy nhất.
Trước khi Unicode ra đời, thế giới đã tồn tại hàng trăm hệ mã hóa, tuy nhiên lại chưa có bất kỳ hệ nào lưu trữ được đầy đủ mọi ký tự. Nổi bật nhất chắc có lẽ là ASCII, bảng mã dựa trên chữ cái Latin được dùng trong tiếng Anh hiện đại.
Chính xác thì ASCII dùng 7 bit biểu diễn với 7 số nhị phân (thập phân từ 0 đến 127). Từ 32 đến 127 là những ký tự in được, tức là hiển thị được, ví dụ ‘ ‘ là 32, chữ cái ‘A’ là 65. Mã dưới 32 được dùng để biểu diễn ký tự điều khiển (control character), ví dụ như nút ESC, Backspace.
Rõ ràng chỉ với 7, thậm chi là 8 bit, bạn chỉ biểu diễn được tối đa 256 ký tự, từng đó quá đủ với tiếng Anh, nhưng với ngôn ngữ khác thì không thể. Vậy các hệ mã hóa khác thì sao? Những hệ mã hóa này lại xung đột với nhau. Ví dụ cả hai đều cùng sử dụng một số để biểu diễn hai ký tự khác biệt, hoặc lại dùng hai số khác nhau để biểu diễn cùng một ký tự. Mỗi một máy tính đều hỗ trợ nhiều chuẩn mã hóa, chính vì vậy mà mỗi khi dữ liệu được trao đổi giữa các chuẩn mã hóa thì nguy cơ sai lệch luôn tồn tại.
Unicode ra đời để giải quyết vấn đề này. Nó cung cấp một biểu diễn số duy nhất cho mỗi một ký tự, mà không cần quan tâm đến nền tảng, chương trình hay ngôn ngữ là gì. Chuẩn Unicode (Unicode Standard) cung cấp một phương thức nhất quán để mã hóa toàn bộ ngôn ngữ viết trên thế giới. Để mã ký tự trông đơn giản và hiệu quả, nó sẽ gán một ký tự với một số duy nhất. Chuẩn Unicode hỗ trợ 3 hình thức mã hóa như mình đã nói ở trên, bao gồm UTF-8, UTF-16 và UTF-32, mã hóa cùng một bộ ký tự, dĩ nhiên.
Bảng mã Unicode
Vậy thì Unicode thực sự là gì? Unicode là một bảng mã, nó ánh xạ một số duy nhất đến một ký tự (ký tự này có thể là chữ cái tiếng Anh như “a”, “b” hoặc tiếng Việt “á”, “ớ”, tiếng Nhật hoặc là các ký tự đặc biệt như “$”, “%”, dấu chấm câu “.”, “,”…)
Mỗi số như vậy được gọi là một điểm mã (code point), một khái niệm mang tính lý thuyết. Còn việc điểm mã được biểu diễn trong bộ nhớ hay ổ đĩa là một câu chuyện hoàn toàn khác. Mỗi điểm mã được biểu diễn dưới dạng U+0639. “U+” tượng trưng cho “Unicode”, còn phần hệ số là hệ hexa. Ví dụ, điểm mã U+0041 là số hexa 0041 (tương đương số thập phân 65). Nó biểu diễn ký tự “A” trong chuẩn Unicode.
Mỗi ký tự được gán một tên duy nhất để phân biệt nó với ký tự khác. Chẳng hạn, U+0041 được gán tên là “LATIN CAPITAL LETTER A”. U+0A1B được gán với tên “GURMUKHI LETTER CHA”.
Lấy ví dụ một xâu ký tự:
Hello
trong Unicode, xâu ký tự này tương ứng với 5 điểm mã (lưu ý là 5 điểm mã chứ không phải 5 byte)
U+0048 U+0065 U+006C U+006C U+006F
Số chữ cái mà Unicode có thể định nghĩa là không giới hạn, trên thực tế nó vượt xa con số 65536. phiên bản Unicode mới nhất là 9.0.0, biểu diễn tổng số 128172 ký tự.
Một số thuật ngữ thường dùng trong Unicode như: không gian mã (code space), plane, code unit, block…
Không gian mã là không gian chứa tất cả các điểm mã của Unicode. Một thuật ngữ khác là plane. Unicode chia thành 17 plane, mỗi plane chứa 65,536 ký tự (tương đương 16 bit), bởi vậy tổng kích thước không gian mã của Unicode là 17 × 65,536 = 1,114,112. Hiện tại với phiên bản Unicode 9.0 mình đã đề cập ở trên thì chỉ sử dụng chưa tới 10% không gian mã. Một điều cần nói thêm là Unicode sẽ hạn chế chỉ với 17 plane, tức là sẽ không xảy ra việc cần tới plane thứ 18 để biểu diễn ký tự, không gian mã với hơn 1 triệu ký tự có thể được mã hóa đã quá đủ cho mục tiêu của Unicode, chính vì vậy mà chuẩn Unicode không có ý định mở rộng thêm không gian mã đến plane thứ 18 hoặc hơn.
Để hiểu hơn về plane, mọi người có thể xem lại định dạng điểm mã Unicode U+0639. Như lúc đầu mình đã nói thì chuẩn Unicode mã hóa ký tự trong dải từ U+0000 đến U+10FFFF. Mỗi plane sẽ sử dụng 65536 ký tự, tương đương từ 0000 – FFFF trong hệ hexa. 17 plane, tức tương đương đánh số thứ tự từ 0 đến 16 trong hệ thập phân, tức là 00-10 trong hệ hexa, 2 số này sẽ chiếm 2 vị trí đầu tiên trong định dạng 6 số (hhhhhh).
Chung quy lại định dạng điểm mã Unicode có dạng U+000639, với “U+” là Unicode, 2 số đầu để mô tả plane, 4 số cuối là điểm mã trong plane đó. Plane đầu tiên gọi là Basic Multilingual Plane, đây là plane quan trọng nhất (plane 0), chứa gần như hầu hết hệ thống chữ viết và ký hiệu thường dùng trên thế giới. Chứa ký tự nằm trong khoảng U+0000 đến U+FFFF.
Đơn vị mã (code unit), thuật ngữ này lại liên quan đến phương thức mã hóa. Chẳng hạn với UTF-8 thì code unit là 1 byte, UTF-16 thì code unit là 2 byte, trong khi UTF-32 là 4 byte.
Blocks: chỉ đơn giản là một dải các điểm mã mà có một đặc điểm chung nào đấy, về mặt ngôn ngữ hoặc chức năng. Chẳng hạn block đầu tiên, từ U+0000 đến U+001F là dải mã để biểu diễn các ký tự điều khiển (control character), gồm 32 ký tự. Block tiếp theo tên là Basic Latin, bắt đầu từ U+0020 đến U+007F, đây cũng chính là dải mã biểu diễn các ký tự trong bảng mã ASCII…
Tiếng Việt của mình thì dùng các ký tự trong block Basic Latin, để biểu diễn các ký tự không dấu, như “a”, “A”. Còn các ký tự có dấu như “á”, “ấ”, “Ớ” thì nằm trong block Latin-1 Supplement, Latin Extended-B và Latin Extended Additional. Thông tin về các Unicode block các bạn có thể tra cứu ở đây.
Các phương thức mã hóa Unicode (Encoding)
Phương thức dịch điểm mã sang nhị phân được gọi là mã hóa ký tự (character encoding). Như đã nói, Unicode có 3 phương thức mã hóa: UTF-8, UTF-16 và UTF-32
UTF-32: đây là phương thức mã hóa Unicode đơn giản nhất. Mỗi điểm mã được biểu diễn trực tiếp bằng một đơn vị mã 32 bit
UTF-16: trong kiểu mã hóa này, mỗi điểm mã trong plane 0 (U+0000 đến U+FFFF) được biểu diễn bằng một đơn vị mã 16 bit, các điểm mã từ plane 1 trở đi cần dùng một cặp đơn vị mã 16 bit để biểu diễn.
UTF-8: tương tự như UTF-32 và UTF-16, kiểu mã hóa này sử dụng đơn vị mã 8 bit, và nó có thể biểu diễn được mọi ký tự trong dải U+0000 đến U+10FFFF, điểm khác biệt duy nhất với 2 kiểu mã hóa trên là UTF-8 tương thích với ASCII.
Trong bài viết này mình sẽ trình bày kỹ về UTF-8, phương thức mã hóa được sử dụng phổ biến nhất hiện nay. Hiểu được cách UTF-8 mã hóa sẽ giúp chúng ta có cái nhìn toàn diện hơn về việc mã hóa ký tự. Một số ưu điểm của nó:
- UTF-8 có thể biểu diễn được mọi điểm mã Unicode
- Nó tương thích của ASCII
- Nó tiết kiệm không gian hơn so với những kiểu mã hóa anh em của nó như UTF-16 hay UTF-32. Ký tự mã hóa theo kiểu UTF-8 có thể nằm trong khoảng từ 1-4 byte. Với văn bản tiếng Anh thông thường thì chỉ cần sử dụng 1-2 byte để biểu diễn một ký tự.
- UTF-8 không yêu cầu sử dụng BOM (byte order mark)
Để thực sự hiểu cách UTF-8 encoding làm việc, chúng ta có thể xem bảng sau, tóm tắt về phương thức mã hóa như sau:
Tìm hiểu thêm: Kinh tế vi mô là gì? Mối quan hệ giữa kinh tế vi mô và kinh tế vĩ mô

>>>>>Xem thêm: C/O Giáp Lưng Là Gì? Cách Xin Cấp C/O | sentayho.com.vn
- Với ký tự chỉ có 1 byte (hầu hết là ASCII), bit đầu tiên sẽ luôn là 0 để tương thích với ASCII
- Với ký tự multi-byte, byte đầu tiên sẽ bắt đầu với từ 2-4 số 1 để biểu diễn số byte ký tự sẽ dùng, theo sau là một số 0
- Phần bit còn lại trong byte đầu tiên và những byte tiếp theo được dùng để điền những bit biểu diễn điểm mã, ngoại trừ việc mỗi byte tiếp theo sẽ bắt đầu với 10
Từ ví dụ U+00A3 chúng ta lấy giá trị thập phân của A3 là 163 và chuyển sang hệ nhị phân, đó là 10100011. Chú ý rằng cần 8 số nhị phân để biểu diễn số này trong hệ nhị phân. Trong khi đó nếu là single-byte thì luôn phải bắt đầu bằng 0 để tương thích với ASCII, thế nên để biểu diễn ký tự có điểm mã là U+00A3 chúng ta cần 2 byte.
Vì là ký từ multi-byte nên byte đầu tiên sẽ bắt đầu bằng hai số 1 để chỉ ra rằng có hai byte cần được sử dụng, theo sau là một số 0, tiếp đến là các bit của điểm mã chúng ta cần điền. Lúc này byte đầu tiên sẽ có dạng là 110xxxxx
Thêm vào đó ở mục 3 mình có đề cập là những byte sau byte đầu tiên luôn được bắt đầu với 10. Vì vậy với 3 bit đầu tiên của byte thứ nhất là 110, 2 bit đầu tiên của byte thứ hai là 10, chúng ta đã dùng 5 bit để sử dụng cho định dạng kiểu mã hóa, lúc này chỉ còn lại 11 bit để lấp đầy bằng điểm mã. Vì giá trị nhị phân của U+00A3 là 10100011, chỉ có 8 bit, ta mặc định thêm 3 số 0 vào đầu nữa cho đủ 11 bit, thành 00010100011, từ giá trị này chúng ta chỉ việc lấp vào số bit còn thừa đã tính ở trên, cắt từ trái sang phải. Như vậy byte đầu tiên sẽ là
11000010
byte tiếp theo sẽ là
10100011
Nếu vẫn còn mập mờ thì bạn có thể xem thêm ví dụ minh họa ở đây, cực kỳ dễ hiểu.
Ứng dụng
Vậy là bây giờ chắc các bạn cũng đã hiểu được phần nào về Unicode và kiểu mã hóa UTF-8 rồi. Hãy thử trả lời mấy câu hỏi sau xem sao nhé (à trên editor nhớ lưu lại với encoding là UTF-8 nhé) =))
$str_jp = ‘た’; $str_vn_1 = ‘á’; $str_vn_2 = ‘ớ’; 1. strlen($str_jp) 2. mb_strlen($str_jp, ‘UTF-8’); 3. $str_jp[0]; 4. $str_jp[0] . $str_jp[1] . $str_jp[2]; 5. strlen($str_vn_1); 6. strlen($str_vn_2);
Đáp án sẽ là
1. 3 2. 1 3. � 4. わ 5. 2 6. 3
Câu thứ 1 và thứ 2 thì đơn giản rồi, strlen đo chiều dài xâu ký tự dựa trên số byte, còn mb_strlen đo chiều dài dựa trên encoding, bộ ký tự tiếng Nhật mã hóa theo UTF-8 thì cần dùng 3 byte, nên strlen trả về 3, còn mb_strlen trả về 1.
Vì kiểu $str[index] sẽ trả về byte tại vị trí index, nên đương nhiên kết quả sẽ lỗi, vì trình duyệt cũng như bộ giải mã không hiểu đây là cái gì, bởi nếu chuyển sang hệ nhị phân thì nó là 11100011, không trùng với bất cứ ký tự nào (facepalm)
Ở câu 4, đơn giản chỉ là nối 3 byte lại với nhau, Unicode sẽ dựa vào byte đầu tiên, cũng chính là 11100011, nó sẽ biết rằng đây là byte định dạng cho ký tự, 3 số 1 chứng tỏ ký tự này cần 3 byte để biểu diễn, thế nên nó chỉ việc tìm thêm 2 byte tiếp theo là sẽ biết được đó là ký tự gì. Vì định dạng của 2 byte sau đều là 10xxxxxx, bạn có thể thử tráo vị trị 2 byte này, sẽ ra được một ký tự khác mà không hề xảy ra lỗi, theo ví dụ trên thì nếu
$str_jp[0] . $str_jp[2] . $str_jp[1]
sẽ cho output là
㏂
ký tự này có điểm mà Unicode là U+33C2 (có vẻ không liên quan lắm) =))
Câu thứ 5 và thứ 6, có lẽ bạn cảm thấy hơi lạ, vì cùng là ký tự tiếng Việt mà lại có độ dài byte khác nhau, nguyên nhân là vì tiếng Việt mình sử dụng ký tự thuộc nhiều block khác nhau, có ở cả Basic Latin (vốn là ASCII, nên chỉ có 1 byte), rồi Latin-1 Supplement, Latin Extended-B và Latin Extended Additional, nên nó có thể có độ dài từ 1 đến 3 byte, và kết quả strlen cũng thay đổi tùy theo ký tự ấy sử dụng bao nhiêu byte.
Vậy là xong, mong rằng qua bài viết này thì bạn cũng có cái nhìn rõ hơn về Unicode và xử lý ký tự bất kể là single-byte hay multi-byte. Thank you for reading!
Tài liệu tham khảo:
- http://unicode.org
- http://www.joelonsoftware.com/articles/Unicode.html
- https://en.wikipedia.org/wiki/UTF-8